
堆排序
堆排序
本文将介绍数据结构堆,以及堆排序
堆
堆是一种
通常堆是通过一维数组来实现的。
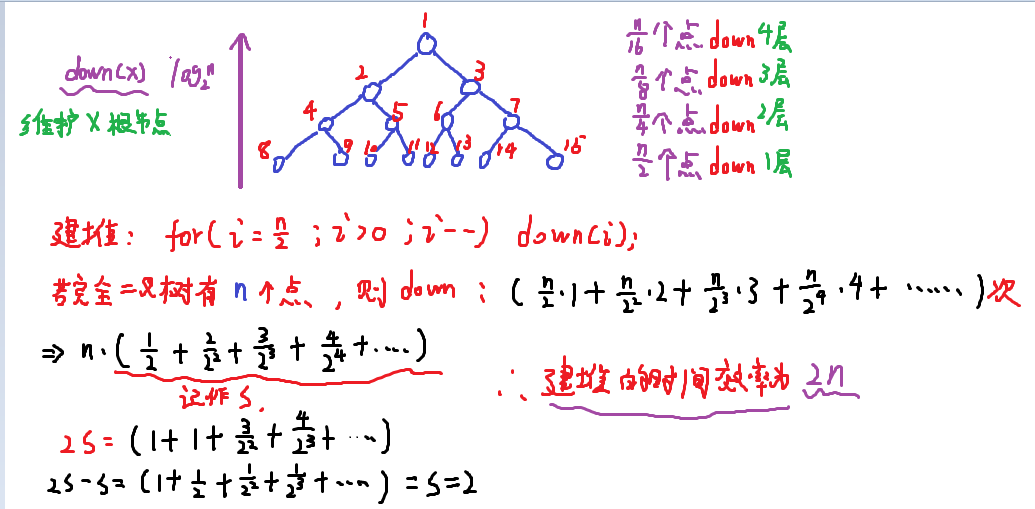
如果根节点的编号是 x 的话,它的左儿子编号是 2x + 1,右儿子编号是 2x + 2。
一个子节点是 p 的话,它的父节点是 ⌊ (p - 1) / 2 ⌋。
如果根节点的编号是 x 的话,它的左儿子编号是 2x,右儿子编号是 2x + 1。
一个子节点是 p 的话,它的父节点是 ⌊ p / 2 ⌋。
在数组起始下标为1的情况下
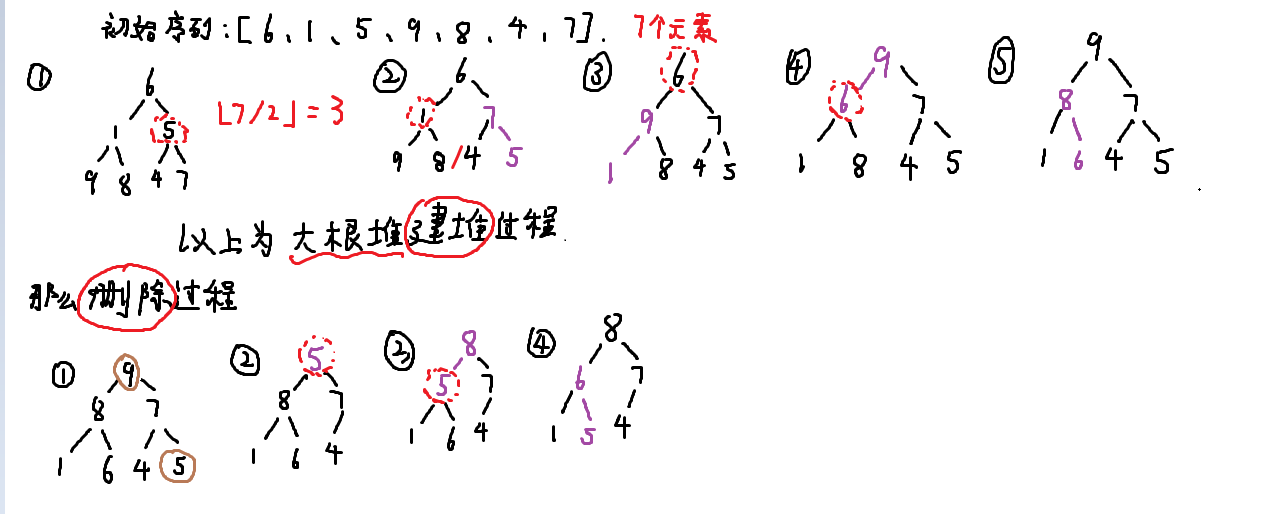
将堆的最后一个元素覆盖堆顶元素,堆的大小减1。(最后一个元素很好删)
然后,从堆顶开始 down 一遍。
算法思想
使用大根堆,基于大根堆的操作基础;堆顶元素总是最大值,每次将堆顶元素与堆中最后一个元素互换,将堆的大小减1,然后 down(1)维护大根堆。反复如此,直到 n 个元素,执行 n - 1 次这样的操作,排序完成。
算法特性
算法模板
需要注意的是,需要维护一个变量 sz,它代表堆的容量
1 | |
技术支持
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Phbeats-Blog!
相关推荐






评论