
快速排序
快速排序
本文将介绍王道书上的快排模板和一种不同于老教材的快排模板,图示是根据考研书上画的
算法思想
快速排序的核心操作为「哨兵划分」,其目标为:
一个简单的例子:
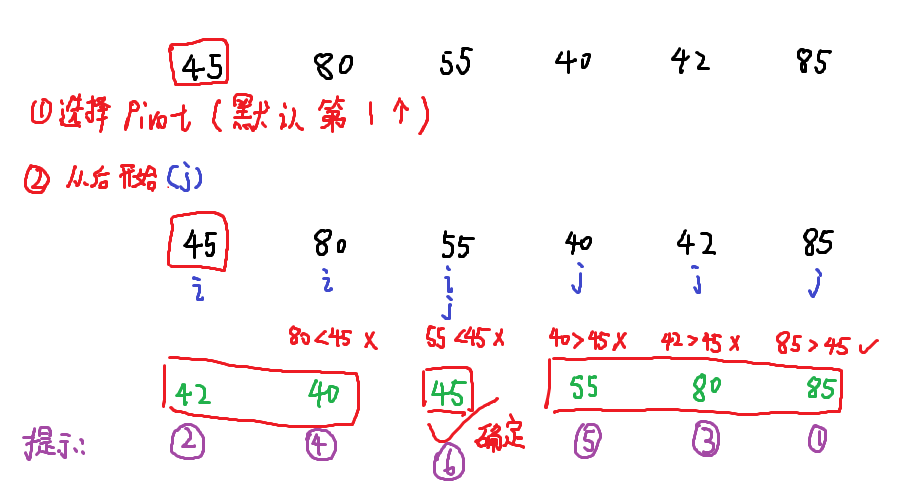
以上是快速排序第一轮的模拟。
算法特性
- 快速排序的
平均情况下的运行时间与其最佳情况下的运行时间很接近都是O(nlogn) - 快速排序的运行时间与划分是否对称有关,
快速排序的最坏情况发生在两个区域分别包含 n - 1 个元素和 0 个元素时 ,这种最大限度的不对称若发生在每层递归上,本应是二叉树的递归树退化成一叉树(单链表),即对应于初始排序表基本有序或基本逆序时,就得到最坏情况下的时间复杂度O(n2) 。
- 最好情况:O(logn) (二叉树)
- 平均情况:O(logn) (二叉树)
- 最坏情况:由于要进行 n - 1 次递归调用,所以栈的深度为O(n)
在快速排序算法中,每趟排序后会将枢轴(基准)元素放到其最终位置上。(考研写法)
快速排序为什么快?
从命名能够看出,快速排序在效率方面一定“有两把刷子”。快速排序的平均时间复杂度虽然与「归并排序」和「堆排序」一致,但实际 效率更高,这是因为:
- 出现最差情况的概率很低:虽然快速排序的最差时间复杂度为 O(n2) ,不如归并排序,但绝大部分情况下,快速排序可以达到 O(nlogn) 的复杂度。
- 缓存使用效率高:哨兵划分操作时,将整个子数组加载入缓存中,访问元素效率很高。而诸如「堆排序」需要跳跃式访问元素,因此不具有此特性。
- 复杂度的常数系数低:在提及的三种算法中,快速排序的 比较、赋值、交换 三种操作的总体数量最少(类似于「插入排序」快于「冒泡排序」的原因)。
算法模板1(背诵适合面试)
1 | |
算法模板2(考研版本)
1 | |
以上两种模板,各有缺点:
第一种模板的pivot最终不一定是在分界点上,而教材上的pivot最终一定是在分界点上的 第二种模板的分界点取每个区间的第一个元素作为pivot,若被卡数据,比如:顺序或逆序,让二叉树退化成一叉链表。这样就会TLE(Time Limit Exceeded)
第一种适合算法模板(短),第二种适合考研写法。
拓展
技术支持
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 Phbeats-Blog!
相关推荐






评论